こちらの記事「VAEを用いたUNIXセッションのなりすまし検出」はソースコードが完全に公開されていないので、補完してみました。
環境
- macOS 10.14
- python 3.7
データ準備
まず、データを準備します。こちらからダウンロードします。ダウンロードしたら、解凍し、Fasttext用にデータを結合します。各ユーザの前半の5000は訓練用のデータで、なりすましがないデータですので、これをすべてのユーザから抽出します。ユーザごとに一行にコマンドをスペースでつないで作成します。全部で五十行になります。
1 | for f in masquerade-data/*;do head -n 5000 $f|perl -pe 's/\n/ /g'|perl -pe 's/$/\n/'>> train.txt; done |
Fasttextによるベクトル化
単語をfasttextによりベクトル化します。50次元を使っています。fasttextはpipでインストールしたものでもOKです。
1 2 3 4 5 6 7 8 | import numpy as np import os import fasttext model = fasttext.train_unsupervised("train.txt", "skipgram", dim=50, minCount=1) |
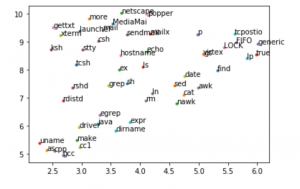
UMAPによる可視化
元記事では出現頻度の高いコマンドから200取り出して、可視化していますが、面倒なので、modelの単語列から上位50単語を抜き出して可視化します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | %matplotlib inline import matplotlib.pyplot as plt import umap import matplotlib.cm as cm np.random.seed(12345) x_word=[model[w] for w in model.words] y_word=model.words embedding = umap.UMAP().fit_transform(x_word[:50]) for emb,lbl in zip(embedding,y_word[:50]): plt.plot(emb[0],emb[1],marker=".") plt.annotate(lbl,(emb[0],emb[1])) # https://teratail.com/questions/110775 plt.show() |
モデル
元記事のものではそのままでは動かなかったので多少修正しています。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 | import numpy as np import keras from keras import layers from keras import backend as K from keras.models import Model from keras.layers.core import Lambda from keras.optimizers import Adam #K.clear_session() shape = (100, 50, 1) epochs = 120 batch_size = 16 latent_dim = 2 input_cmd = keras.Input(shape=shape) x = layers.Conv2D(32, 3, padding='same', activation='relu')(input_cmd) x = layers.Conv2D(64, 3, padding='same', activation='relu', strides=(2, 2))(x) x = layers.Dropout(0.1)(x) x = layers.Conv2D(64, 3, padding='same', activation='relu')(x) x = layers.Dropout(0.2)(x) x = layers.Conv2D(64, 3, padding='same', activation='relu')(x) x = layers.Dropout(0.2)(x) shape_before_flattening = K.int_shape(x) x = layers.Flatten()(x) x = layers.Dense(32, activation='relu')(x) z_mean = layers.Dense(latent_dim)(x) z_log_var = layers.Dense(latent_dim)(x) def sampling(args): z_mean, z_log_var = args epsilon = K.random_normal(shape=(K.shape(z_mean)[0], latent_dim), mean=0., stddev=1.) return z_mean + K.exp(z_log_var) * epsilon z = Lambda(sampling)([z_mean, z_log_var]) decoder_input = layers.Input(K.int_shape(z)[1:]) x = layers.Dense(np.prod(shape_before_flattening[1:]), activation='relu')(decoder_input) x = layers.Reshape(shape_before_flattening[1:])(x) x = layers.Conv2DTranspose(32, 3, strides=(2, 2), padding='same', activation='relu')(x) x = layers.Conv2D(1, 3, padding='same', activation='sigmoid')(x) decoder = Model(decoder_input, x) z_decoded = decoder(z) class CustomVariationalLayer(keras.layers.Layer): def vae_loss(self, x, z_decoded): x = K.flatten(x) z_decoded = K.flatten(z_decoded) xent_loss = keras.metrics.binary_crossentropy(x, z_decoded) kl_loss = -5e-4 * K.mean( 1 + z_log_var - K.square(z_mean) - K.exp(z_log_var), axis=-1) return K.mean(xent_loss + kl_loss) def call(self, inputs): x = inputs[0] z_decoded = inputs[1] loss = self.vae_loss(x, z_decoded) self.add_loss(loss, inputs=inputs) return x y = CustomVariationalLayer()([input_cmd, z_decoded]) |
1 2 3 4 5 | vae = Model(input_cmd, y) vae.compile(optimizer=Adam(), loss=None) vae.summary() |
入力データ
入力データを作成します。ファイルから再度読み込んで、訓練データを上位4000コマンド、テストデータを4001から5000コマンドで作成します。また、元記事と同様にUser2を使っています。
1 2 3 4 5 6 7 8 9 | with open("masquerade-data/User2") as f: cmds=[l.rstrip() for l in f.readlines()] x=[model[cmd] for cmd in cmds] x_train=np.reshape(np.array(x[:4000]),(40,100,50,1)) x_valid=np.reshape(np.array(x[4000:5000]),(10,100,50,1)) |
訓練
Earlystoppingを入れました。訓練は100コマンドをひとかたまりとして訓練しています。
1 2 3 4 5 6 7 8 9 10 | from keras.callbacks import EarlyStopping es_cb = EarlyStopping(monitor='val_loss', patience=50, verbose=1, mode='auto') history = vae.fit(x=x_train, y=None, shuffle=True, epochs=epochs, batch_size=batch_size, validation_data=(x_valid, None), callbacks=[ es_cb]) |
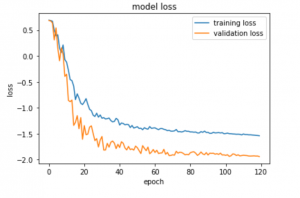
結果の可視化
訓練データでのLossを可視化します
1 2 3 4 5 6 7 8 9 10 11 12 13 | %matplotlib inline import matplotlib.pyplot as plt plt.plot(history.history["loss"],label="training loss") plt.plot(history.history["val_loss"],label="validation loss") plt.title("model loss") plt.xlabel("epoch") plt.ylabel("loss") plt.legend(loc="upper right") plt.show() |
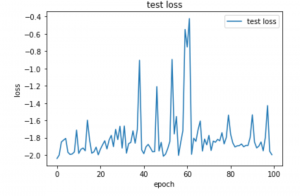
テスト
最後に、1%の確率でなりすましが入っているという各ユーザの5001行目からのデータをつかって、Lossを可視化します。同様に100コマンドをひとかたまりとして、100個分をテストしています
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | x_test=np.reshape(np.array(x[5000:]),(100,100,50,1)) loss_test=[] for i in range(len(x_test)): loss_test.append((vae.evaluate(x=np.reshape(x_test[i],(1,100,50,1)),y=None))) %matplotlib inline import matplotlib.pyplot as plt plt.plot(loss_test,label="test loss") plt.title("test loss") plt.xlabel("epoch") plt.ylabel("loss") plt.legend(loc="upper right") plt.show() |